The full research and development report can be downloaded in pdf format (LANL only).
We have converted the source ISI files (used by the SciSearch database) for 1996, 1997, 1998, and some of 1999 (source files from now on) into a repository of records in XML format. These records contain all essential bibliographic, keyword (semantic), and citation (structure) information about published documents that we require for ARP research and development. The XML marked up format allows us much higher ease of access and retrieval of documents. We believe that other LWW efforts can profit from this format, so we have designed an XML structure that is general enough for other future usage. We specify here the details of this repository (1).
The ISI files we had access to are organized in two categories:
The source files are organized in three sequentially hierarchical levels:
These levels are organized in the following way:
File data
source issue data
record data
citation data
citation data
citation data
record data
citation data
citation data
end source issue data
source issue data
record data
citation data
citation data
citation data
record data
citation data
citation data
end source issue data
end file data
The markup language of the source files defines a unique identifier for each line, defined by two characters and followed by a space and the respective attributes. Example:
"
LA EN English
AV Y
AB In this paper, the authors propose a circumferential bursting pressure form
-- ula for pressure vessels that are made by being helically wound with steel
-- ribbon. They have analyzed axial and circumferential strengths from the bur
-- vessel
BP 7
EP 11
PG 5
DT @ Article
LA EN English
"
The maximum line length is 80 characters. Lines that exceed this length are broken down into separate lines (titles and abstracts mostly). The tag is not repeated for each individual line but replaced by a continuation tag: '--' (see example above). Citations are marked within the limits of a record segment with citation start and end tags: CR ...EC. Within such a citation block other tags exist to identify bibliographic information such as author (/A), year (/Y), etc. Example:
CR
/A ABATE, C
/Y 1993
/W P NATL ACAD SCI USA
/V 90
/P 6766
EC
The full, detailed specification of the XML records is also available . Our XML records contain a unique identifier for any and all ISSN and ISBN documents referred to as an ARPID. Each record also contains CITATION, BIBLIOgraphic, and KEYTERMS information.
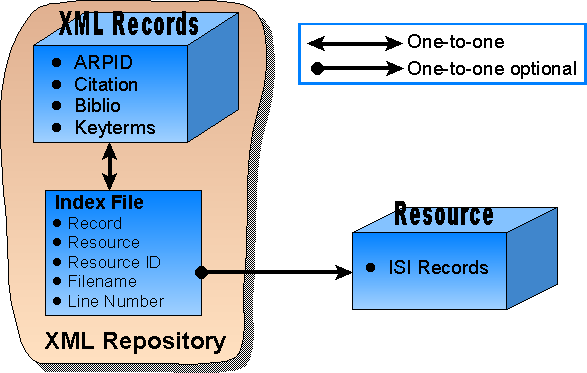
The current XML Repository design collects information available for each published document (including keywords) in XML records. An index file then associates each XML record with possible multiple instances of records of the same document in different information resources. This does not accommodate the fact that references to the same document in different information resources might not be identical. Some of these differences may be trivial (e.g. spelling difference in titles, author first name abbreviation); others more substantial (e.g. different keywords, perhaps as supplied by the vendor, and even different keyword types). There are a number of possible solutions, ranging from ignoring these differences (first record in wins) to factoring out keyword information for separate storage, to recording completely redundant XML records for each corpus entry.
The current XML Repository design is illustrated in the figure below. A record of a document is identified in the ISI source files, and its ARPID is calculated. The citation, bibliographic and keyterm data are also stored in the respective XML record. The index file is then used to identify (and retrieve) the correspondence between any XML record and its ISI source file counterpart. Thus, the index file contains only pointers to records in the XML repository and source resources such as the ISI source files currently used (see 1.2.2).
Now consider the situation where more than one information resource is to be used, as shown in figure 2. As a document is read from the new resource, its ARPID is looked up in the XML repository. If it identified in the index file, only a new index entry is added, not a new XML record. Otherwise, both are added. Now we have a one-to-many relation between the XML records and the index file in the XML repository: for each XML record, there exists at least one index entry. In other words, the same XML record may now be indexed more than once by index file pointers to different records of the same document in different information resources. This way, the index file can contain entries with the same ARPID (and XML record pointers), but with pointers to different external resources and Resource IDs.
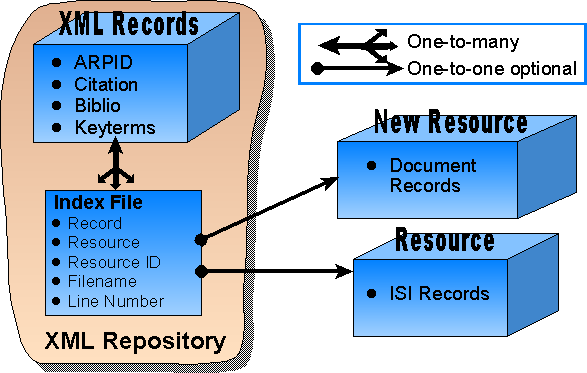
There are a few problems about this current set up that need to be clear. When new information resources become available, the XML records need to be updated with new information collected. The most obvious updating is the keyterm information which may be different in the correspondent information resource records for the same document; different resource owners will possess different schemes for standardizing keywords. Furthermore, even bibliographic information may be distinct due to spelling differences in titles, author first name abbreviation, etc.
Clearly, differences in bibliographic (or citation) data should not concern us too much since they originate from errors that we cannot control and which will always be present in endeavors such as ARP. When identified, these distinctions should be considered errors, and the information from one resource should be chosen over the others.
Keyterm differences, on the other hand, should not be ignored since they reflect meaningful information supplied by the information resource owners. The issue therefore is how to update the XML records with new information, namely, new keyterm types. Our XML specification, as discussed in 1.2.1, easily allows the creation of new keyterm types. The problem is in the implementation of the XML repository in extremely large flat-files with XML records. Updating or rewriting text in such large files is a very time and space intensive task.
Clearly, the XML repository indexed by different information resources is a relational structure, and would be better served by a proper relational database implementation rather than the flat-files we employ. We are evaluating SQL products for this project, particularly, for the relational repository discussed next in section 2. We will study the suitability of using such products also for the XML repository.
Short of a proper relational database, our only solution to improve this problem is to work with smaller text files. We are investigating the best way to achieve this breakup. Two solutions seem feasible:
Since we are currently using only one information resource (the ISI source files), this problem is not stalling the progress of ARP. We will keep on studying this problem and its two identified solutions, particularly by assessing the effectiveness of the implementation of the relational repository, which can give us an indication of the merits of solution 2 above.
As discussed in 1.2.1, the XML record repository recognizes only documents (records or citations) which possess an ISSN or ISBN. By default all records from the source files have ISSN's because ISI stores only journals with ISSN's. The citations, on the other hand, may cite documents with no ISSN. The programming details of the way we construct the ARPID's with ISSN information can be seen in Appendix A of the full report (LANL Only). An ISSN lookup utility was put on the web for easy testing: http://bighorn.lanl.gov:8077/cgi-bin/ISSNlookup.cgi.
As discussed in 1.2, we allow for different types of keywords in the XML records. So far, given the ISI data, we use author-supplied, ISI+, and title keywords as well as author names. We generated the title keywords to obtain some semantic information for the many records which do not possess the first two kinds of keywords (about a third of all records). The title keywords were obtained from the document titles after extraction of common words judged without semantic interest and subsequent stemming to avoid different occurrences of the same semantic topic. The algorithm we used for stemming keywords was put on the web as a cgi application for easy testing: http://bighorn.lanl.gov:8077/cgi-bin/stem.cgi. The most common words for each of the three categories of keywords can be accessed on the web.
For the semantic analysis we have in mind, as described below in section 2, we use all three kinds of keywords, after consistent stemming, interchangeably. In other words, we create a super-set of all the three different types of keywords and use them as semantic tokens. Some of this data is available at http://www.c3.lanl.gov/~rocha/lww/keywords.html.
The XML repository resides in the TURBO machines at CIC-3. The exact location of all files, including the relational repository described in section2 below, is described on the web at http://web.c3.lanl.gov/~jbollen/LWW/turbo_filestructure_spec.txt (LANL Only).
1. The implementation details of the production of the XML repository are described in the full report in Appendix A (LANL Only).
2. In section 2, and in the separate document Joslyn [1999] (LANL Only) we discuss the benefits of supplementing the source files with pre 1996 ISI data.

