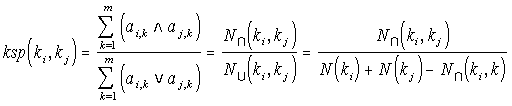
The full research and development report can be downloaded in pdf format (LANL only).
From the XML record repository we derive the data structures which allow our algorithms to operate and are the raw materials for all research and development. Essentially, this repository refers to all relational information between records and keywords and between records and citations: the semantics and the structure respectively. Notice that relational is not used here in the sense of relational databases, but in the sense that to infer semantics from information resources, we need the relations between keywords and documents, and to infer structure we need the relations between records and citations. This semantic and structural relational repository is an important asset that can be used by other efforts other than ARP, therefore it is important to document it well.
From the XML record repository, we now possess a unique record ID (the ARPID) for each document in the databases that ARP accesses. Let each ARP record be identified by rj, j=1...m.Currently, we have records from the source files for 3 years and a half (1996-1999). In this data, in addition to the m records, we have n keywords ki and set of cited documents S (1). Notice that S, is larger than the set of records R, and that these sets overlap only partially. In fact, if we were to use only one year worth of data, this overlap would be very small, potentially empty. Furthermore, the two sets are not nested, that is, neither R⊆S nor S⊆R. For structural analysis we need to create the citation document set D = R∪S of all the p documents dl involved in a citation relation
From the XML repository we can derive all database semantic information since this is inferred from the relationships between the set the set of records R and the set of all keywords K used the records of R. Therefore, all semantic treatment needs only to deal with K and R. To obtain the citation structure we need to calculate D and the relations between S and R.
From the XML record repository we obtain the set of all records R. This is an ordered list file of all the unique ARPID's, essentially the (uniqued) index file of section 1.2.2; m = 2,915,258. We also obtain the set of all keywords K. This is an alphabetically ordered list file of all unique keywords in the XMLrepository after stemming. We removed single keywords (those used by a single record), and generated a file of unique keywords and associated documents to use in case more documents end up using these keywords in the future. Until a keyword is used by more than one document, it has no semantic relational value for us. Thus, we are only considering keywords which qualify at least two records; n=839,297.
From the repository we produce the Keyword-Record Matrix A: n � m matrix, of n keywords ki and m records rj. Each entry ai,j in the matrix is boolean and indicates whether keyword ki qualifies (1) record rj or not (0).
A is a very sparse matrix, so it is implemented in a double adjacency-list representation, that is, as two adjacency-list sparse matrices, one indexed by keywords, and the other indexed by records. We created a system called 1 File Per IDentifier (FIPID) to store this very large matrix, whose specifications are described in detail in the full report (LANL Only).
The Keyword Semantic Proximity Matrix KSP. It is a square matrix of dimension n. For two keywords ki and kj, it is the number of records they both qualify, over the number of records either one qualifies. Proximity varies in the unit interval, and is defined by the following equation:
The semantic proximity calculations between two keywords, ki and kj, depends on the sets of records qualified by either keyword, and the intersection of these sets. N(ki) is the number of records keyword ki qualifies, and N(ki, kj) the number of records both keywords qualify. This last quantity is the number of elements in the intersection of the sets of records that each keyword qualifies.
KSP is implemented as single adjacency-list sparse representation since it is a symmetrical matrix. However, we do not store actual proximity values, but rather the three quantities: N(ki), N(kj), and N(ki, kj) for each pair of keywords. This makes it possible to add more records to the repositories without having to recalculate the intersection above again. Each time a new record qualified by kiand/or kj is added to the repository, we add 1 to both/either counts N(ki) and N(kj). If both ki and kj qualify the new record, we also add 1 to N(ki, kj). Furthermore, the adaptive algorithms we employ, change these counts rather than the proximity values themselves. The same FIPID scheme used to store A is also used to store KSP; details in the full report (LANL Only).
A list of keyword semantic proximity values for the 100 most frequent keywords can be accessed on the web at: http://www.c3.lanl.gov/~rocha/lww/KWproximity100.html.
The Record Semantic Proximity Matrix RSP, is a square matrix of dimension m. For two records ri and rj, it is the number of keywords that qualify both, over the number of keywords that qualify either one. This proximity is the dual measure of the keyword semantic proximity calculated from A. It varies in the unit interval, and it is defined by the following equation:
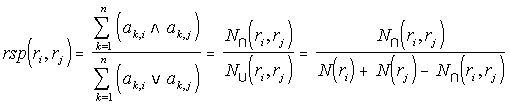
The semantic proximity calculations between two records, ri and rj, depends on the sets of keywords qualifying either record, and the intersection of these sets. N(ri) is the number of keywords that qualify record ri, and N(ri, rj) the number of keywords that qualify both records. This last quantity is the number of elements in the intersection of the sets of keywords that qualify each record qualifies. The same FIPID scheme used to store A is also used to store RSP; details in the full report (LANL Only).
Given the number of keywords n=839,297 and the number of records m=2,915,258, KSP and RSP are very large matrices with 7.05 � 1011, with 3.5 � 1011 relevant entries (due to symmetry). With our current computational power, to calculate one of these matrices completely in less than 10 years, each entry in the matrix needs to be calculated under .01 seconds. This value actually ranges from 2-3 seconds for the most frequent keywords, to .0001 to least frequent keywords, so it is not trivial to predict how long exactly it would take to compute such matrices - not instantaneously!
Therefore, we have decided to permanently compute these values for the most frequent keywords, and for user-requested keywords. In other words, we will be going down the list of most frequent keywords calculating new proximity values as time passes. Furthermore, since we have the ability to compute proximity values for sufficiently large sets of keywords (20-30) in acceptable time, when users issue requests for proximity values not yet calculated, we can calculate and store them in real time. Notice that since we have been calculating the proximity values for the keywords at the top of the most frequent list, user requests not yet calculated will refer to proximity values that are much faster to calculate. The proximity values of keywords of non-requested, non-frequent keywords, may never be calculated, but these are also not necessary.
A list of keyword semantic proximity values for the 100 most frequent keywords can be accessed on the web at: http://www.c3.lanl.gov/~rocha/lww/KWproximity100.html.
Several operations have been created to query the Semantic Relational Repository. The details of these can be be found on the full report (LANL Only). These operations return neighborhoods of submatrices of A, KSP, and RSP.
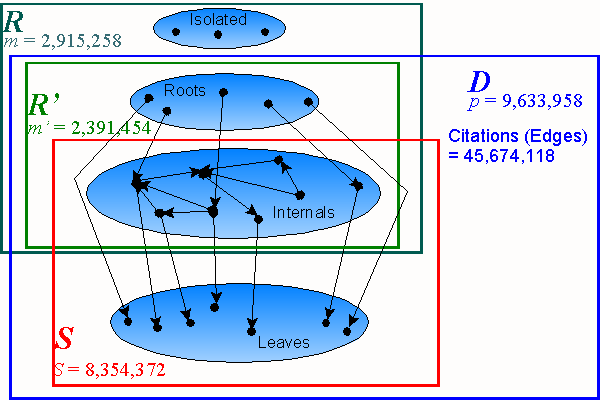
From the XML record repository we obtain the citation document set D in the source files. From the m= 2,915,258 records of R we discovered that 523,804 records refer to documents that do not cite any other documents: isolated documents (2). Thus, as far as the citation structure is concerned, we possess a set R' of records, m'= 2,391,454, referring to documents which participate in a citation relation with other documents. Of these, we have 1,279,586 root and 1,111,868 internal records. The former are records that refer to documents which cite other documents but are not cited by documents for which we have records in the XML repository. The latter are records which cite other documents and are cited by documents in our records.
The documents contained in the set R' also cite 7,242,504 documents for which we do not have records in the XML repository: the leaves of the citation structure (3). Therefore, the set of cited documents S contains 8,354,372 documents: the internals (which we have records of) plus the leaves (which we do not have records of). The complete citation document set D contains p=9,633,958 documents (roots + internals + leaves), which are the nodes of the citation structure seen below.
A more complete citation analysis of the structural relational repository has been performed by Cliff Joslyn. It can be found at: http://web.c3.lanl.gov/~joslyn/lww/citations.pdf.
NOTE:ARP makes the citation matrix publicly available under the condition that any use of this data acknowledges the Active Recommendation Project at the Los Alamos National Laboratory. The citation matrix and the Active Recommendation Project are described in a publication by Rocha and Bollen.
The Citation Matrix C is a p � p matrix, of p documents dl of D. This is a very sparse matrix implemented in an adjacency-list representation, that is, as an adjacency-list of citations in the format:
ARPIDi ARPIDj
where ARPIDi cites ARPIDj
ARPIDs are unique publication identifiers created for ARP for its XML Repository -- full, detailed specification of the XML records including ARPIDs is also available
In the citation matrix, ARPIDs with x's refer to publications for which we do not have full records, that is, we do not know their own citation and keyword information (they are the leaves of the citation graph as described above). ARPIDs with x's occur only in the second column. For the other ARPIDs we have full record information (authors, keywords, abstract, citation data, etc.) in our XML Repository. In any case, the ARPID itself contains enough information to uniquely identify a specific paper.
The adjacency matrix file is available as a gzipped tab-delimited file (aprox 450MB)
The Inwards Structural Proximity Matrix Pin is a square matrix of dimension p. For two documents di and dj, it is their direct co-citation [Small, 1973], that is, the number of documents that cite di and dj, over the number of documents that cite either di or dj, . Documents that cite di are referred to as ancestors of di. The Inwards Proximity varies in the unit interval and is defined by:
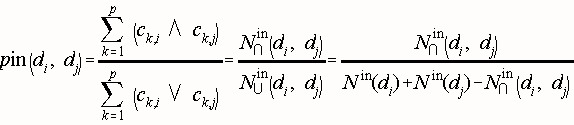
N in(di) is the number of documents that cite document di, and Nin (di, dj) the number of documents that cite both di and dj. This matrix is also implemented with the FIPID system; details in the full report (LANL Only).
The Outwards Structural Proximity Matrix Pout is a square matrix of dimension p. For two documents di and dj, it is their direct bibliographic coupling [Kessler, 1963] that is, the number of documents that both di and dj cite, over the number of documents that either di or dj cite . Documents that di cites are referred to as descendants of di. The Outwards Proximity varies in the unit interval and is defined by:
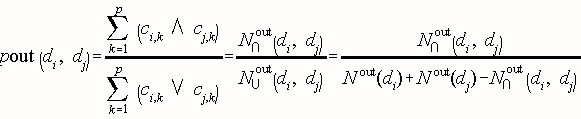
N out(di) is the number of documents that document di cites, and Nout (di, dj) the number of documents that both di and dj cite. This matrix is also implemented with the FIPID system; details in the full report (LANL Only).
Several operations have been created to query the Structural Relational Repository. The details of these can be be found on the full report (LANL Only). These operations return neighborhoods of submatrices of C, Pin, and Pout.
1. In this section, keywords refer to the super-set of all the three different kinds of keywords in the XML repository: author, ISI+, and Title.
2. These may also contain documents who cite only books, since we are only considering documents with ISSN for the time being. Notice also that even though these documents are isolated as far as the citation structure is concerned, they are linked by the semantic relations of section 2.1.
3. Even tough we do not have records of these leave documents, we are able to create ARPIDs for them because we obtain the necessary bibliographic information from the citation information of the records of the documents that cite them (roots and internals).

